Nuestras fuentes
Cuando se comprueban los documentos por plagio y pasajes citados incorrectamente, es importante que se incluya cada una de las fuentes disponibles. Sólo así, se puede confiar en los resultados que se muestran en el informe de plagio.
PlagScan incluye automáticamente cuatro tipos de fuentes en su rutina de detección de plagio:
- 'Internet' con 14 billones de contenidos digitales disponibles, directamente a su alcance.
- Millones de artículos científicos y académicos en revistas de las editoriales más prestigiosas del mundo.
- Su propia base de datos con documentos de tesis o trabajos anteriores (opcional).
- La Preventeca de Plagio de PlagScan con contenido de otros participantes de la Preventeca.
Después de examinar las fuentes, extraemos miles de textos semánticamente similares y los escaneamos cuidadosamente para buscar coincidencias con su documento.
Más detalles sobre las fuentes:
Internet
Utilizamos Microsoft Bing como pilar fundamental de indexción web para mejorar nuestra búsqueda de contenidos digitales. De esta manera, nos aseguramos de estar constantemente al día, con los últimos contenidos que se publican en Internet. Por lo tanto, siempre puede estar seguro de que nuestra solución encontrará los últimos artículos disponibles.
Millones de artículos en revistas académicas
Mediante la cooperación con varias de las editoriales científicas de mayor renombre en todo el mundo, nos aseguramos de que, independientemente del campo de investigación, se pueda acceder a todos los artículos publicados sobre ese tema, incluso a través de la barrera de suscripciones. Los profesores e instructores pueden, por lo tanto, concentrarse en el contenido del trabajo real que fue presentado, ahorrando un tiempo preciado en la lectura y la verificación cruzada de cada uno de los artículos sobre ese tema específico.
PlagScan actualmente incluye más de 10.800 revistas y 14 millones de artículos de las siguientes editoriales, y constantemente añade más:
- BMJ
- Gale, a Cengage company
- Taylor & Francis
- Wiley Blackwell
- Springer
- Y muchos más
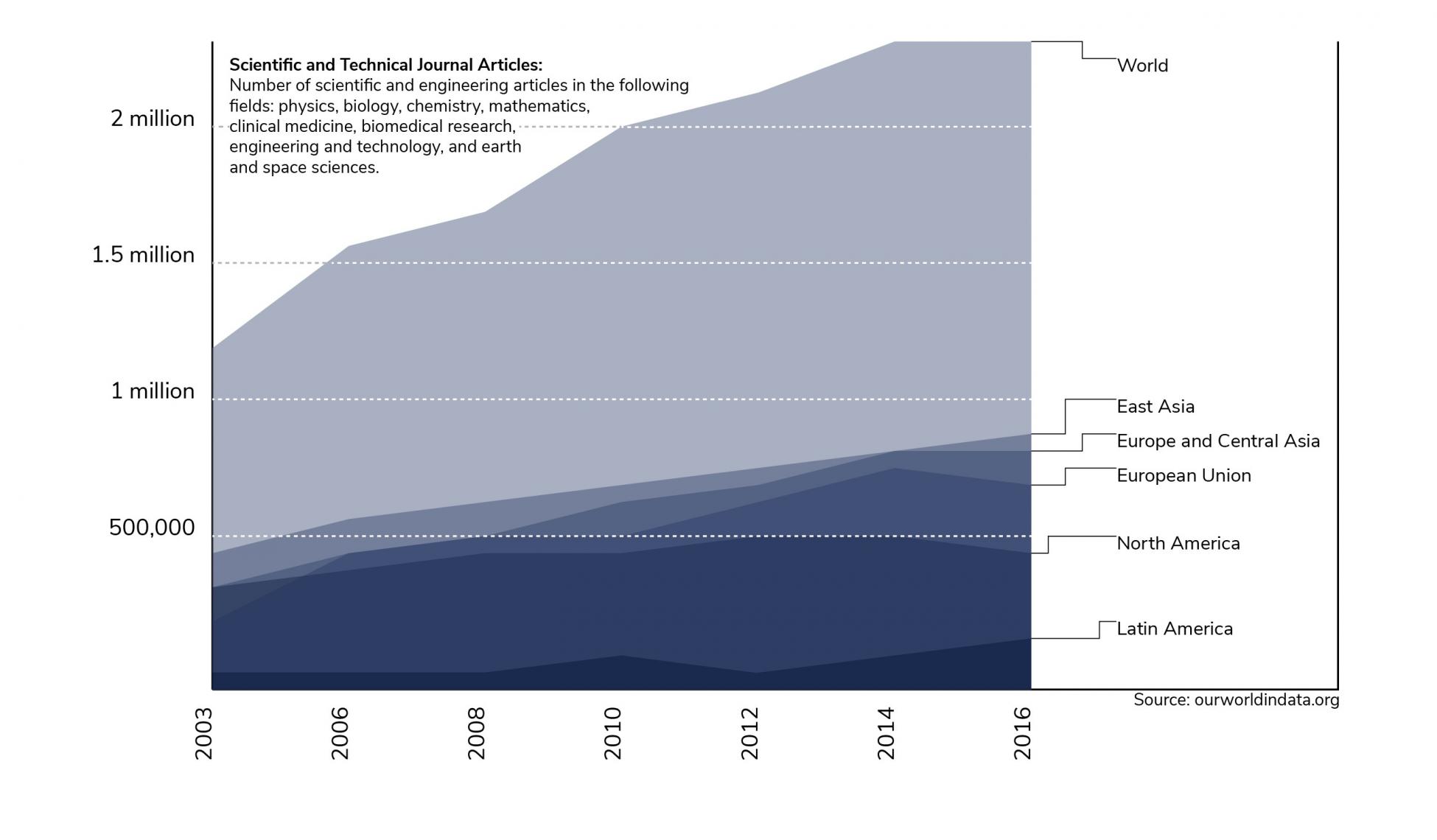
Hoy en día, se publican más de 2,6 millones de artículos al año en revistas en revisión por partes

Comprobación de colisión con sus propios documentos
No importa si su organización es una universidad, una escuela o una empresa: Hay muchas posibilidades de que alguien más ya haya escrito un documento sobre el tema asignado o discutido. PlagScan proporciona la oportunidad de crear su propia base de datos consistente en anteriores entregas, tesis o artículos que han sido añadidos a su repositorio. Esto le asegura la originalidad de cada documento presentado.
Documentos en la Preventeca de Plagio de PlagScan
Los usuarios de PlagScan pueden participar en la preventeca de Plagio de PlagScan. Como una forma de asegurar que las universidades puedan analizar los trabajos en diferentes regiones y asegurarse de que no se han presentado ya en otra universidad o escuela. Este índice de documentos enumera todos los documentos presentados, y asegura que el mérito se otorgue a quien lo merece. Lea más sobre la Preventeca de Plagio de PlagScan aquí.
Nuestro algoritmo
Tres coincidencias consecutivas de palabras constituyen el elemento básico de nuestro algoritmo de detección de plagios para encontrar finalmente el plagio a pesar de que el texto esté reordenado o contenga sinónimos.
Al final del proceso de detección, aplicamos la inteligencia artificial para identificar citas directas, coincidencias insignificantes y contenido de la lista blanca, con el fin de presentarle unos resultados más completos.
Nuestra tecnología de indexación interna se basa en Apache Solr™.

Tecnología Made in Germany
La sede de PlagScan está en Alemania junto con el desarrollo de nuestro software y el alojamiento de nuestros servidores. Salvaguardamos los derechos de autor y actuamos de acuerdo con la Ley Federal Alemana de Protección de Datos.
Hemos heredado el "gen de ingeniería alemán" en nuestro ADN y reflejamos los más altos estándares posibles de calidad.
