Unsere Datenquellen
Bei der Überprüfung von Dokumenten auf Plagiate und falsch zitierte Passagen ist es wichtig, dass jede einzelne verfügbare Quelle mit einbezogen wird, gegen die geprüft werden kann. Nur dann können Sie sich auf die im Plagiatsbericht gezeigten Ergebnisse verlassen.
PlagScan nimmt automatisch vier Arten von Quellen in seine Plagiatserkennungsroutine auf:
- „Das Internet“ mit über 14 Milliarden digitalen Inhalten, die Ihnen zur Verfügung stehen.
- Millionen von wissenschaftlichen und akademischen Artikeln in Journals der renommiertesten Verlage der Welt.
- Ihre eigene Dokumentendatenbank mit früheren Abschlussarbeiten oder Einreichungen (optional).
- Der Plagiats-Präventions-Pool mit Inhalten von anderen Teilnehmern des Pools.
Nach der Überprüfung der Quellen extrahieren wir tausende von semantisch ähnlichen Texten und scannen sie sorgfältig nach Übereinstimmungen in Ihrem Dokument.
Mehr Details zu den Quellen:
Das Internet
Wir verwenden Microsoft Bing als Basis, um unser Crawling für digitale Inhalte zu verbessern. Auf diese Weise stellen wir sicher, dass wir immer auf dem neuesten Stand der im Internet veröffentlichten Inhalte sind. So können Sie immer davon ausgehen, dass unsere Lösung die neuesten verfügbaren Artikel enthält.
Millionen von Artikeln in wissenschaftlichen Journals
Durch die Zusammenarbeit mit mehreren der renommiertesten Wissenschaftsverlage weltweit stellen wir sicher, dass unabhängig vom Forschungsgebiet jeder veröffentlichte Artikel zu dem jeweiligen Thema zugänglich ist – auch über eine Bezahlschranke hinweg. Professoren und Dozenten können sich so auf den Inhalt der eingereichten Arbeit konzentrieren und wertvolle Zeit sparen, anstatt jeden einzelnen Artikel zu diesem speziellen Thema lesen und überprüfen zu müssen.
Zusätzlich zu tausenden Open-Access-Zeitschriften umfasst PlagScan derzeit über 10.800 Journals und 14 Millionen Artikel, die von folgenden Verlagen veröffentlicht werden – und wir fügen ständig neue hinzu:
- BMJ
- Gale, a Cengage company
- Taylor & Francis
- Wiley Blackwell
- Springer
- Und viele mehr
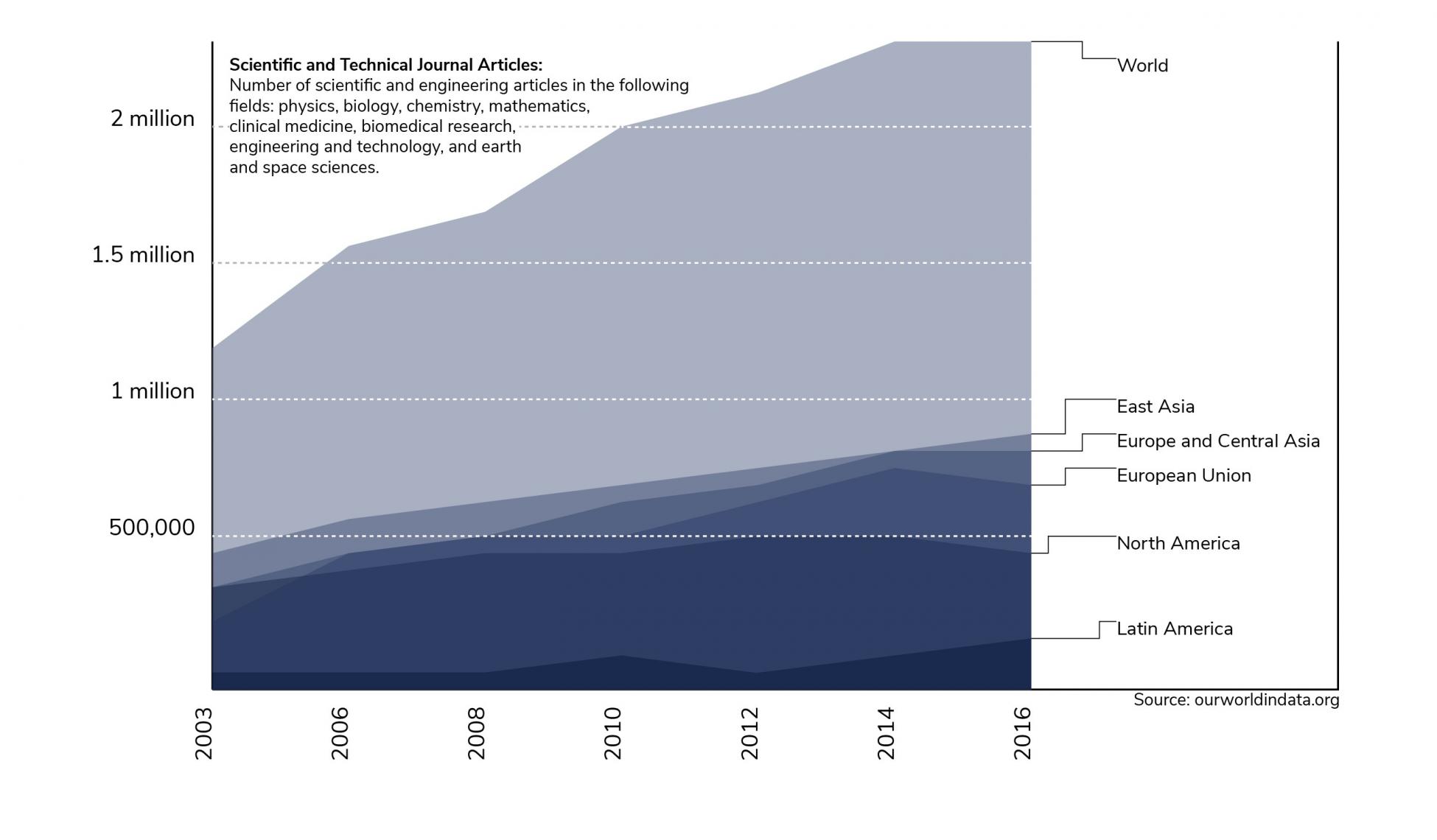
Heute werden jährlich mehr als 2,6 Millionen Artikel in Peer-Review-Journals veröffentlicht.

Kollusionsprüfung mit eigenen Dokumenten
Ganz gleich, ob es sich bei Ihrer Organisation um eine Universität, eine Schule oder ein Unternehmen handelt: Die Chancen stehen gut, dass jemand anderes bereits ein Dokument zu dem zugewiesenen oder diskutierten Thema geschrieben hat. Optional bietet PlagScan die Möglichkeit, eine eigene Datenbank aufzubauen, die aus Einreichungen, Abschlussarbeiten oder Artikeln besteht, die Ihrem Archiv hinzugefügt wurden. Dadurch wird die Originalität jedes eingereichten Dokuments gewährleistet.
Dokumente aus dem Plagiats-Präventions-Pool
Um zu gewährleisten, dass Universitäten Einreichungen aus verschiedenen Regionen gegeneinander abgleichen können und sicherzustellen, dass sie nicht bereits an einer anderen Universität oder Schule eingereicht wurden, können PlagScan-Anwender am globalen Plagiats-Präventions-Pool teilnehmen. Dieser Dokumentenindex listet alle eingereichten Dokumente auf und stellt sicher, dass Ehre denen gebührt, die sie verdienen. Erfahren Sie mehr über den Plagiats-Präventions-Pool.
Unser Algorithmus
Drei aufeinanderfolgende Wörter stellen das Basiselement unseres Algorithmus dar, um auch bei potentiellen Satzumstellungen und Synonymen immer noch deutliche Übereinstimmungen zu identifizieren.
Nachdem die Übereinstimmungen gefunden wurden, wenden wir einen intelligenten Filter an, um viele offensichtlich legitime Übereinstimmungen auch nicht anzuzeigen. Dazu gehören direkte Zitate, unbedeutend kleine Übereinstimmungen und alles, was sie auf ihre 'weiße Liste' gesetzt haben, um ein maximal informatives Resultat zu liefern.
Wir haben unsere hauseigene Indexierungstechnologie entwickelt, basierend auf Apache Solr™.

Technologie Made in Germany
PlagScans Hauptquartier, Technologie und Server stehen in Deutschland. Da wir somit dem deutschen Datenschutzgesetz unterliegen, schützen wir alle einkommenden Daten und legen Wert auf die Einhaltung von Urheberschutz und Gesetzen.
Wir haben das „German Engineering Gene“ in unsere DNS übernommen und spiegeln somit die höchsten Qualitätsstandards wider.

Sie wollen mehr über das Thema erfahren?
- Lesen Sie Antworten auf häufig gestellte Fragen in unseren FAQs
- Kontaktieren Sie uns